
Questões de Banco de Dados
Lista completa de Questões de Banco de Dados para resolução totalmente grátis. Selecione os assuntos no filtro de questões e comece a resolver exercícios.
-
A) pode ser categorizada como: aditiva, semi-aditiva e não aditiva.
B) deve ser normalizada.
C) tem apenas uma coluna chave primária.
D) também é chamada de tabela de medidas.
-
A) a tabela central, com relacionamento para todas as outras, é a tabela de dimensões.
B) as informações de fatos são normalizadas e as informações de dimensões são desnormalizadas.
C) a inclusão de cubos OLAP deve ser feita durante a etapa de normalização.
D) as informações são classificadas em 3 grupos: fatos, dimensões e medidas.
-
A) star schemas.
B) cubos OLAP.
C) data marts.
D) tabelas de dimensões.
Um técnico da equipe de TI do TJRN recebeu a tarefa de adicionar o tjusr para ter acesso ao banco de dados PostgreSQL (versão 12). O técnico, logado como administrador do PostgreSQL, digitou os seguintes comandos:
CREATE USER tjusr PASSWORD 'senhatemporaria';
REVOKE ALL ON processo FROM tjusr;
GRANT SELECT ON processo TO tjusr;
GRANT USAGE, SELECT ON ALL SEQUENCES IN SCHEMA public TO tjusr;
Após a execução desses comandos, o usuário tjusr poderá
-
A) realizar consultas no banco de dados processo.
B) realizar consultas e atualizar dados no banco de dados processo.
C) adicionar um novo usuário ao banco de dados processo.
D) realizar exclusão de dados no banco de dados processo.
O PostgreSQL permite criar funções para facilitar operações diárias e abstrair a complexidade na leitura e utilização dos códigos. Isto posto, analise a função a seguir:
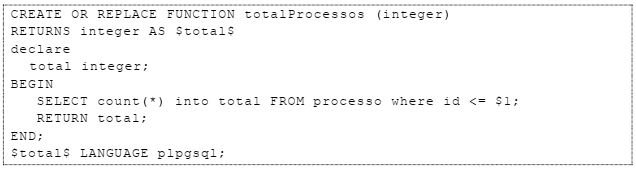
Sobre essa função, é correto afirmar que ela
-
A) não recebe parâmetros e retorna um texto.
B) retorna um número de ponto flutuante.
C) retorna um número do tipo inteiro.
D) não pode ser invocada em uma outra consulta.
Considerado um importante componente da área de Business Intelligence (BI), o DataWarehouse pode fazer uso de diversas fontes de dados. Considere as afirmações abaixo sobre DataWarehouse.
I Faz uso intensivo de operações de escrita e pouco uso de operações de leitura.
II É projetado para tarefas analíticas, oferecendo dados para tomada de decisão.
III Seus dados são projetados e estruturados de maneira normalizada.
IV Contém dados em diferentes níveis, podendo esses dados serem atômicos ou sumarizados.
Estão corretas as afirmações
-
A) I e IV.
B) I e III.
C) II e III.
D) II e IV.
-
A) Volume e Velocity.
B) Variety e Value.
C) Viable e Vast.
D) Valid e Verbose.
-
A) pode ser considerado um repositório de dados relacionados, sendo, portanto, um armazém de dados orientado por assunto.
B) pode ser considerado um conjunto de bancos de dados relacionais e com relacionamentos entre tabelas de diferentes esquemas de bancos de dados.
C) é o resultado de sucessivas operações de mineração de dados, sendo um ambiente no qual é possível ter relatórios e dashboards de maneira amigável para os analistas de negócio.
D) é projetado para armazenar dados de diversas fontes e formatos, não havendo a necessidade da definição de um esquema de dados para inserir novos itens.
-
A) FROMJSON
B) OPENJSON
C) AS_JSON
D) READ_JSON
-
A) drill across.
B) pivot.
C) slice and dice.
D) roll up.

O Provas e Concursos é um banco de dados de questões de concursos públicos organizadas por matéria, assunto, ano, banca organizadora, etc
