
Questões de Ciência da Computação do ano 2006
Lista completa de Questões de Ciência da Computação do ano 2006 para resolução totalmente grátis. Selecione os assuntos no filtro de questões e comece a resolver exercícios.
Nas questões 53 até 60 considere um banco de dados relacional constituído pelas tabelas X, Y e Z, cujas instâncias são mostradas a seguir.
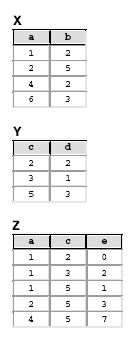
O comando SQL
select zz.*
from x xx left join z zz on xx.a=zz.a
produz:
- A.

- B.

- C.

- D.

- E.

Nas questões 53 até 60 considere um banco de dados relacional constituído pelas tabelas X, Y e Z, cujas instâncias são mostradas a seguir.
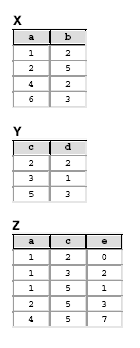
Observe o resultado de uma consulta mostrado a seguir.
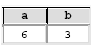
O comando SQL que NÃO produz o resultado acima é:
- A.
select x.*
from x
where not exists (select * from z where z.a=x.a)
union all
select y.*
from y
where not exists (select * from z where z.c=y.c)
- B.
select 6 a, 3 b
union
select y.*
from y
where not exists (select * from z where z.c=y.c)
- C.
select x.*
from x
where not exists (select * from z where z.a=x.a)
- D.
select x.*
from x
where not exists (select * from z where z.a=x.a)
union select 6,3
- E.
select x.*
from x
where not exists (select * from z where z.a=x.a)
union all
select 6,3
Nas questões 53 até 60 considere um banco de dados relacional constituído pelas tabelas X, Y e Z, cujas instâncias são mostradas a seguir.
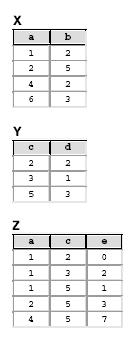
Considere que o diagrama ER, mostrado a seguir na notação IDEF1X com os atributos omitidos, reflete corretamente a estrutura dos relacionamentos existentes entre as entidades X, Y e Z, e que estas entidades correspondem às tabelas homônimas.
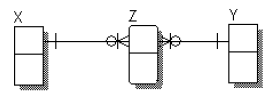
Supondo-se que nenhum dos atributos que constituem as chaves estrangeiras das tabelas tenha sido renomeado ou removido, pode-se concluir que:
- A. os atributos a e c são as chaves primárias das tabelas X e Y, respectivamente;
- B. o atributo e não é parte da chave primária da tabela Z;
- C. os atributos a e b constituem a chave primária da tabela X;
- D. os atributos a, c, e constituem a chave primária da tabela Z;
- E. o atributo e da tabela Z não pode conter valores nulos.
Nas questões 53 até 60 considere um banco de dados relacional constituído pelas tabelas X, Y e Z, cujas instâncias são mostradas a seguir.
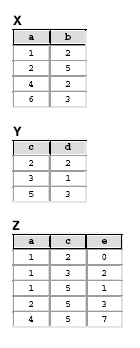
O comando SQL
select x.a,sum(z.e) as s
from x, y, z
where x.a=z.a and y.c=z.c
group by x.a
produz como resultado:
- A.

- B.

- C.

- D.

- E.

Nas questões 53 até 60 considere um banco de dados relacional constituído pelas tabelas X, Y e Z, cujas instâncias são mostradas a seguir.
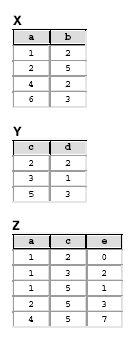
– Considere uma tabela relacional R, com atributos atômicos A, B e C, na qual o atributo A é a chave primária. Sabendo-se que as dependências funcionais
A  B
B
B C
AB C
se verificam, pode-se concluir que a tabela R está normalizada até a:
- A. primeira forma normal;
- B. segunda forma normal;
- C. terceira forma normal;
- D. forma normal Boyce_Codd;
- E. quarta forma normal.
Nas questões 53 até 60 considere um banco de dados relacional constituído pelas tabelas X, Y e Z, cujas instâncias são mostradas a seguir.
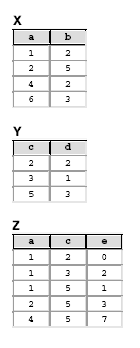
Considere a seguinte especificação de uma chave estrangeira:
alter table T
add constraint C foreign key (x) references T;
Supondo-se que o atributo x não seja um identificador de T, essa construção corresponde, num diagrama ER, a:
- A. dependências funcionais circulares;
- B. um auto-relacionamento 1:N;
- C. um auto-relacionamento N:N;
- D. uma estrutura de generalização;
- E. uma estrutura de especialização.
Analise as informações abaixo, referentes a três das regras de Codd para bancos de dados relacionais:
I. A capacidade de manipular um conjunto de dados (relação), através de um simples comando, deve se estender às operações de inclusão, alteração ou exclusão de dados.
II. Programas de aplicação permanecem logicamente inalterados quando ocorrem mudanças no método de acesso ou na forma de armazenamento físico.
III. Mudanças nas relações e nas views provocam total impacto nas aplicações.
É correto o que se afirma em
- A.
I, apenas.
- B.
II, apenas.
- C.
I e II, apenas.
- D.
I e III. apenas.
- E.
I, II e III.
Habilidade de uma sub-classe de objetos especializar uma operação herdada, redefinindo a implementação da operação mas não a sua assinatura, é a definição de
- A.
agregação.
- B.
polimorfismo.
- C.
generalização.
- D.
encapsulação.
- E.
composição.
Na SQL Server, a sintaxe correta para apagar o índice CL_lastname da tabela employees é:
- A.
DROP INDEX CL_lastname FROM employees
- B.
DROP INDEX CL_lastname
- C.
DROP INDEX employees(CL_lastname)
- D.
DROP INDEX CL_lastname ON employees
- E.
DROP INDEX employees.CL_lastname
Na seqüência do nível de armazenamento para o nível lógico do usuário, a arquitetura ANSI/SPARC de um sistema de banco de dados se divide nos níveis
- A.
externo, conceitual e interno.
- B.
externo, interno e conceitual.
- C.
interno, conceitual e externo.
- D.
interno, externo e conceitual.
- E.
conceitual, externo e interno.

O Provas e Concursos é um banco de dados de questões de concursos públicos organizadas por matéria, assunto, ano, banca organizadora, etc
