
Questões de Ciência da Computação do ano 2014
Lista completa de Questões de Ciência da Computação do ano 2014 para resolução totalmente grátis. Selecione os assuntos no filtro de questões e comece a resolver exercícios.
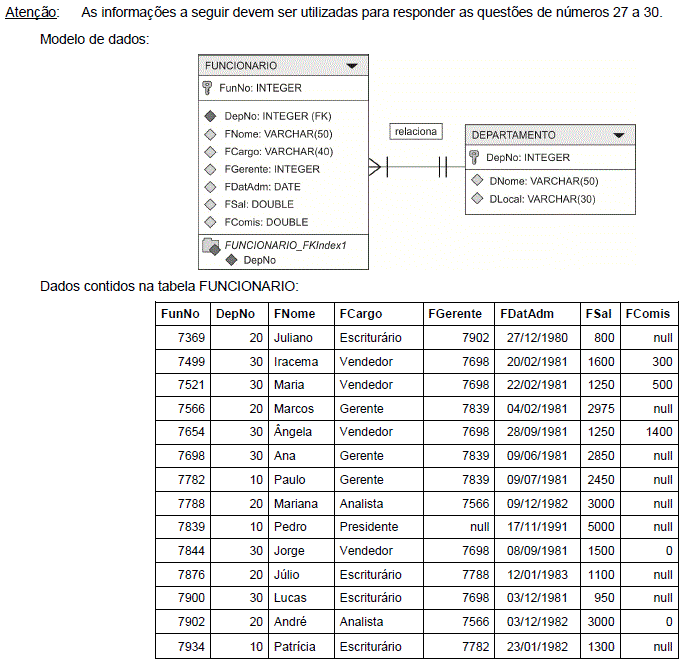
- A. create subtable FUNCIONARIO01 as select FunNo, FNome, FCargo, FSal+FComis as FSalTotal from FUNCIONARIO where DepNo=30;
- B. create table FUNCIONARIO01 as select FunNo, FNome, FCargo, FSal+FComis as FSalTotal from FUNCIONARIO where DepNo=30;
- C. alter table FUNCIONARIO01 as select FunNo, FNome, FCargo, FSal+FComis as FSalTotal from FUNCIONARIO where DepNo=30;
- D. create table FUNCIONARIO01 as select FunNo, FNome, FCargo, FSal+FComis from FUNCIONARIO where DepNo=30;
- E. create table FUNCIONARIO01 as select FunNo, FNome, FCargo, FSal*FComis as FSalTotal from FUNCIONARIO where DepNo=30;
A utilização de ferramentas CASE para modelagem de dados é muito importante para a qualidade do modelo, bem como para garantir uma documentação atualizada e maior facilidade de manutenção de sistemas em produção. Existem no mercado várias ferramentas CASE para este propósito, entre comerciais e gratuitas como as citadas abaixo:
I. É uma ferramenta gratuita e de código aberto para modelagem de dados que trabalha com o modelo lógico, desenvolvida pela fabFORCE sob a licença GNU GPL. É um software multiplataforma (Windows e Linux) implementado em Delphi/Kylix. Além de permitir a modelagem, criação e manutenção de bancos de dados, esta ferramenta possibilita também a engenharia reversa, gerando o modelo de dados a partir de um banco existente, e ainda possibilita o sincronismo entre o modelo e o banco. Foi construída originalmente para oferecer suporte ao MySQL, porém também suporta outros SGBDs como Oracle, SQL Server, SQLite e outros que permitam acesso via ODBC. II. É uma ferramenta desenvolvida pela empresa Popkin Software. Tem a vantagem de ser uma ferramenta flexível para a empresa que trabalha com a Análise Estruturada de Sistemas. Tem como característica importante o fato de ser uma ferramenta workgroup, ou seja, é possível compartilhar um mesmo projeto entre diversos analistas de desenvolvimento. Em um único repositório são colocadas todas as informações do projeto. Os projetos podem ser agrupados por sistemas e subsistemas; existe uma enciclopédia do SA correspondente a cada um deles. Essas enciclopédias ficam armazenadas na rede de acordo com as áreas de trabalho dos analistas. III. É uma ferramenta CASE para modelagem de dados relacional e dimensional, que permite a construção de modelos de dados lógicos e modelos de dados físicos, comercializada pela CA (Computer Associates). Permite ao usuário trabalhar com três tipos de modelos de dados: somente lógico (Logical Only), somente físico (Physical Only) ou lógico e físico (Logical/Physical). Antes da versão 4, todo modelo de dados tinha, obrigatoriamente, o modelo lógico e o modelo físico juntos, ou seja, o modelo sempre era do tipo Logical/Physical. Em versão recente, foi incluído o recurso de derivação de modelos que permite gerar um modelo de dados a partir de outro. Também oferece o recurso de sincronização entre os modelos de dados (Sync with Model Source). As ferramentas CASE I, II e III são, respectivamente:- A.

- B.

- C.

- D.

- E.

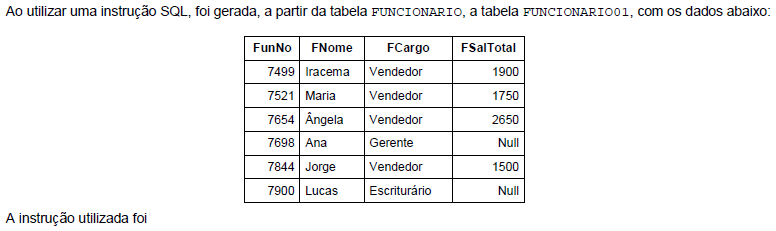
 Um banco de dados relacional consiste em uma coleção de tabelas, cada uma das quais com um nome único. De acordo com a terminologia do modelo relacional e a tabela processo, é correto afirmar:
Um banco de dados relacional consiste em uma coleção de tabelas, cada uma das quais com um nome único. De acordo com a terminologia do modelo relacional e a tabela processo, é correto afirmar:
- A. Os nomes das colunas são chamados domínios. Exemplos: ano_processo e numero_processo.
- B. Para cada domínio há um conjunto de valores permitidos, chamado atributo. No caso de ano_processo poderia ser de 1950 a 2013.
- C. Um valor de domínio que pode pertencer a qualquer domínio possível é o valor vazio, que indica que um valor é zero, desconhecido ou não existe.
- D. Para todas as relações r, os atributos de todos os domínios de r devem ser atômicos. Por exemplo, o conjunto dos números inteiros de vara_processo é um atributo atômico.
- E. Como as tabelas em essência são relações, podem-se usar os termos relação e tupla no lugar de tabela e linhas. A tupla 3 da tabela processo teria os dados (120/3,1019997, 2006).

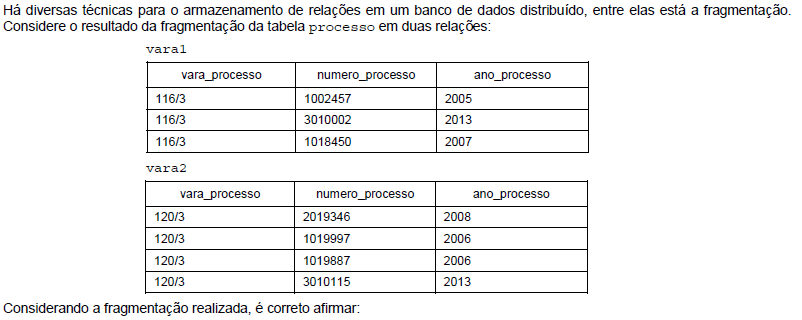
- A. Na fragmentação realizada, os fragmentos são excludentes. Porém, mudando o predicado para a seleção usada na construção dos fragmentos, pode haver uma determinada tupla replicada em mais de uma relação.
- B. Cada tupla da relação original não precisa estar representada nos fragmentos resultantes, pois a tabela original continua armazenada no banco de dados.
- C. A relação original processo pode ser reconstruída usando o comando SQL UNIONTABLE, que uniria os fragmentos vara1 e vara2.
- D. A relação processo foi submetida a uma fragmentação vertical.
- E. A fragmentação realizada resultou em apenas 2 fragmentos vara1 e vara2 porque havia apenas 2 varas diferentes na relação original, portanto, esta é a única fragmentação possível.

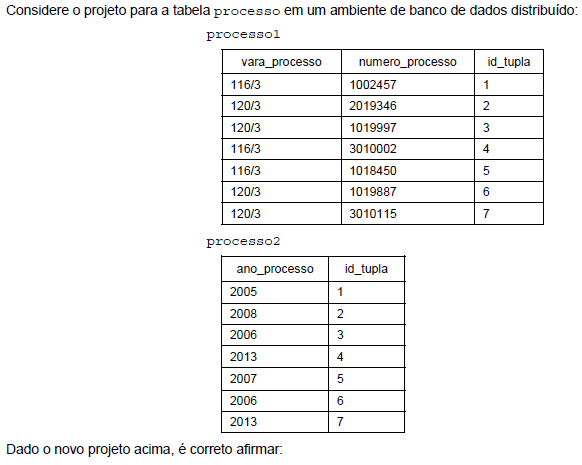
- A. A relação processo foi submetida a uma fragmentação mista, que une a fragmentação horizontal e a vertical, a melhor técnica a ser aplicada neste exemplo.
- B. O único modo de garantir que a relação original possa ser reconstruída é incluir os atributos da chave primária da relação processo em cada um dos fragmentos, portanto, este projeto é inválido.
- C. Embora o atributo id_tupla facilite a implementação da fragmentação, é um artifício interno e viola a independência de dados, uma das principais características do modelo relacional.
- D. O endereçamento físico ou lógico para uma tupla deve ser usado a partir de sua chave primária. Portanto, id_tupla deve ser a chave estrangeira na relação processo2.
- E. O atributo especial id_tupla é um valor único e foi acrescentado para permitir a fragmentação horizontal da relação original.
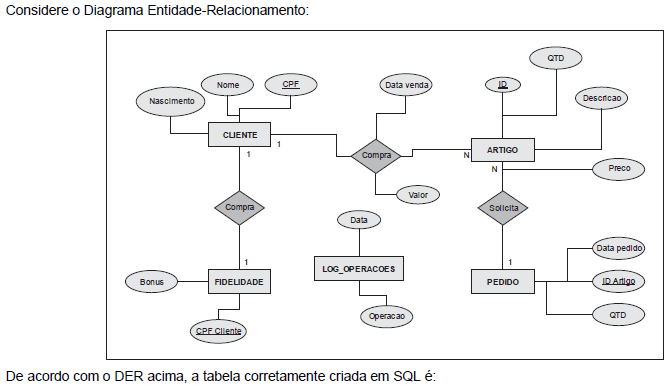
- A. CREATE TABLE CLIENTE( cpf varchar(15) PRIMARY KEY, nome varchar(100) NOT NULL, nascimento data;
- B. CREATE TABLE ARTIGO( id integer PRIMARY KEY, descricao varchar(60) NOT NULL, qtd integer NOT NULL, preco number NOT NULL);
- C. CREATE TABLE FIDELIDADE( cpf_cliente varchar(15) PRIMARY KEY, bonus NUMBER, FOREIGN KEY(cpf) REFERENCES CLIENTE(cpf_cliente));
- D. CREATE TABLE LOG_OPERACOES( date data NOT NULL, operacao varchar(200));
- E. CREATE TABLE PEDIDO( id_artigo int, data_pedido date NOT NULL, qtd int NOT NULL, FOREIGN KEY(id_artigo) REFERENCES ARTIGO(id), PRIMARY KEY(id_artigo, data_pedido));
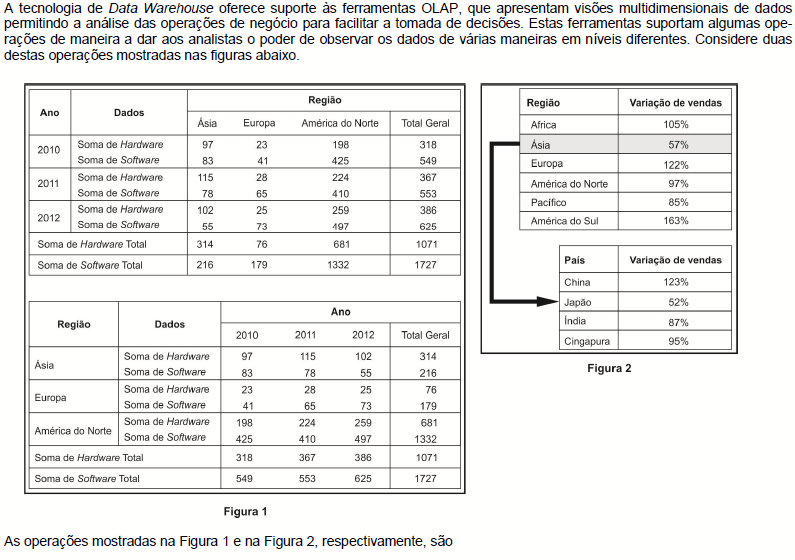
- A. rotação e drill-down.
- B. ROLAP e drill-through.
- C. rotação e roll-up.
- D. roll-up e rotação.
- E. drill-down e ROLAP.

- A. Android, iOS e Windows Phone.
- B. Linux, Windows e Unix.
- C. AIX, Linux e Unix.
- D. AIX, Windows e Linux.
- E. Linux, Unix e AIX.
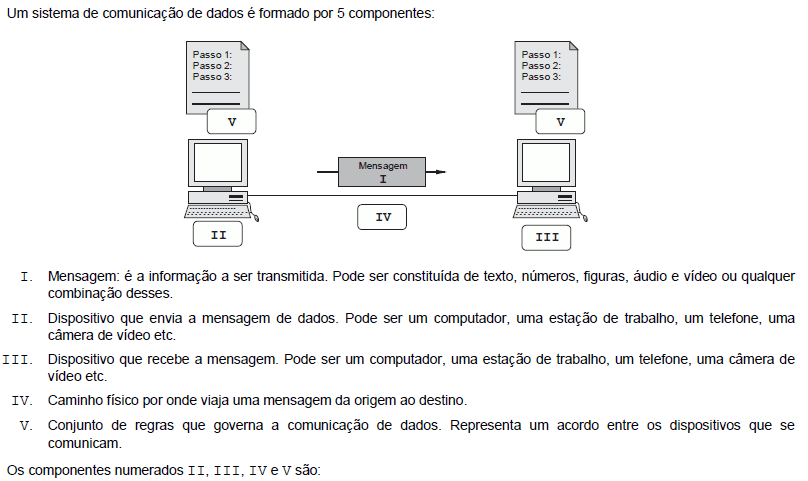
- A.

- B.

- C.

- D.

- E.

Para o CobiT, os controles gerais são controles inseridos nos processos de TI e serviços. Já os controles inseridos nos aplicativos de processos de negócios são comumente chamados de controles de aplicativos. Considere os seguintes itens:
1. Gerenciamento de mudanças. 2. Totalidade. 3. Veracidade. 4. Validade. 5. Segurança. 6. Operação de computadores. São exemplos de controle gerais e exemplos de controles de aplicativos, respectivamente,- A.

- B.

- C.

- D.

- E.


O Provas e Concursos é um banco de dados de questões de concursos públicos organizadas por matéria, assunto, ano, banca organizadora, etc
