
Questões de Ciência da Computação da Fundação Getúlio Vargas (FGV)
Lista completa de Questões de Ciência da Computação da Fundação Getúlio Vargas (FGV) para resolução totalmente grátis. Selecione os assuntos no filtro de questões e comece a resolver exercícios.
(Para resolver esta questão, vide o banco de dados BD_EXEMPLO, descrito no início desta prova) Supondo que as tabelas do banco estejam normalizadas corretamente, e considerando as instâncias apresentadas, a dependência funcional que é satisfeita é
- A. inscrição - candidatoNome
- B. candidatoNome - inscrição
- C. data - provaNome
- D. inscrição - nota
- E. data - provaNome, inscrição
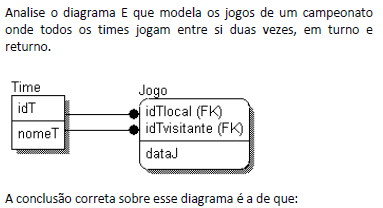
- A. cada jogo é identificado pelos identificadores dos times que o disputam;
- B. o atributo dataJ é o identificador principal da entidade Jogo;
- C. cada jogo é identificado pelos times que o disputam e a data do jogo;
- D. a relação entre as entidades Time e Jogo é de 1:n;
- E. os atributos idTlocal e idTvisitante podem receber valores nulos na implementação do banco de dados.
(Para resolver esta questão, vide o banco de dados BD_EXEMPLO, descrito no início desta prova)

Num mapa de bits para a mesma tabela, usando apenas o atributo Inscrição, o mapa de bits seria
- A.
101 10001001000
102 01000100100
105 00100010010
106 00010000001
- B.
101 1000
102 0100
105 0010
106 0001
- C.
101 10000000000
102 01000100000
105 00100000000
106 00010000000
- D.
101 00000001000
102 00000000100
105 00000000010
106 00000000001
- E.
101 111
102 111
105 111
106 011

- A. E2 é uma especialização de E;
- B. o atributo A é identificador de E2;
- C. E1 possui um atributo B;
- D. E1 e E2 têm entre si um relacionamento 1:n;
- E. B é o atributo discriminador de subtipo.
Considere um arquivo sequencial, com 10.000 registros, cujas chaves identificadoras são números inteiros de até 8 dígitos. Para criar um índice tipo hashing para esse arquivo, contendo endereços de 0 até 11.999, a mais adequada definição para uma função de hashing f(x), onde x é uma chave e (a mod b) é o resto da divisão de a por b, seria
- A. f= x mod 1000 + 12
- B. f = x mod 12000
- C. f= x / 10000
- D. f = x / 11999
- E. f= (x 11999) /10000
João implementou um banco de dados no MS SQL Server que possui uma tabela contendo textos de sentenças judiciais, que são atualizadas esporadicamente, e disponibilizou um aplicativo que permite consultas nessa base de dados. Alguns de seus clientes, entretanto, precisam efetuar consultas onde é preciso localizar registros que possuem duas ou mais palavras próximas umas da outras, como por exemplo, menor de idade. Para que as consultas produzidas pelo aplicativo possam resolver esse tipo de requisição com tempos de resposta aceitáveis, a solução adequada para João seria a utilização de:
- A. índices do tipo clustered;
- B. índices do tipo hash;
- C. índices full-text;
- D. tabelas particionadas;
- E. user-defined functions de manipulação de strings.
Sobre os atributos atômicos W, X, Y, Z, aplicam-se as seguintes dependências funcionais:

Considerando que, nos esquemas apresentados, cada chave é representada por um ou mais atributos sublinhados por um segmento de reta contínuo, o esquema R que satisfaz a Forma Normal Boyce-Codd (FNBC) é
- A. R(W, X, Y, Z), onde W é a única chave.
- B. R(W, X, Y, Z), onde W e Y são chaves distintas.
- C. R(W, X, Y, Z), onde Y é a única chave.
- D. R(W, X, Y, Z), onde W, Y e Z são chaves distintas.
- E. R(W, X, Y, Z), onde a única chave é formada pela concatenação de W,X,Y,Z.
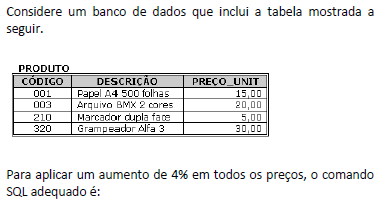
- A. increment preço_unit in produto by 4%
- B. set preço_unit=preço_unit*1.04 on produto
- C. update produto set preço_unit=preço_unit*1.04
- D. write preço_unit as preço_unit*1.04 for produto
- E. update produto with preço_unit as preço_unit*1.04
Considere um esquema relacional R e seus atributos atômicos.

Nesse caso, nota-se que o projeto
- A. não cumpre o objetivo de estabelecer uma decomposição sem perda.
- B. não provê independência de dados.
- C. produz uma tabela que viola a primeira forma normal.
- D. produz duas tabelas que violam a Forma Normal Boyce-Codd.
- E. produz uma implementação que não suporta transações atômicas.
No âmbito do projeto de bancos de dados, os Axiomas de Armstrong têm um importante papel porque permitem a derivação de dependências funcionais. Uma derivação que NÃO é válida é:
- A. se X → Y e Y → Z então X → Z
- B. se X → Y então XZ → YZ
- C.

- D. se X → Y e X → Z então X → YZ
- E. se X → Y e Z → Y então X → YZ

O Provas e Concursos é um banco de dados de questões de concursos públicos organizadas por matéria, assunto, ano, banca organizadora, etc
